基于大数据的空气质量评估和模拟平台
(一)功能
(1) 基于海量环境基础数据,结合社会、经济、地理和气象等数据,利用人工智能机器学习模型,在空间网格层面上,实现任意网格二氧化碳排放的改变,对空气质量影响的定量评估;快速、有效地推动中国和地方温室气体和大气污染物协同管理;
(2) 在地图中精准、全面地展示空间公里网格的排放情况,包括不同部门排放数值和总排放结构特征。有利于用户和决策者快速、精准地掌握排放格局和排放特征;
(3) 实现二氧化碳排放空间网格和中国空气质量监测站点在地图上的交互使用;支撑利用二氧化碳排放网格,评估监测站点的设置和布局。
(二)模型方法
模型目标
模型的总体目标是探究二氧化碳排放数据与PM2.5之间的潜在关系。具体而言包括预测与仿真:1)预测。利用环境监测站点以及站点周围的网格点的二氧化碳排放数据,对站点的PM2.5数值进行预测;2)仿真。解释二氧化碳指标与PM2.5指标之间的具体关系,当改变二氧化碳指标时,能够模拟出环境监测站点PM2.5的变化量。
技术路线
以下为本项目详细的技术路线图:
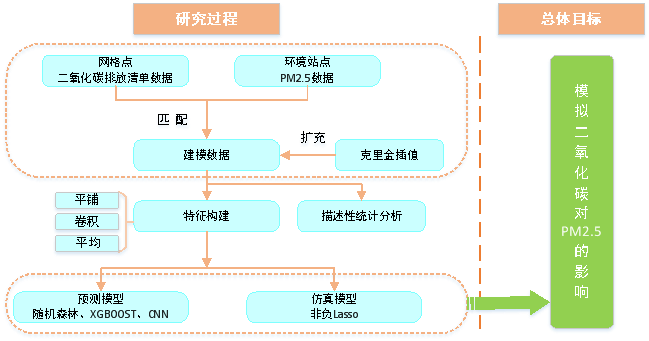
图 1 建模技术线图
技术路线,总体而言,就是对全国网格二氧化碳排放清单数据、全国监测站点PM2.5数据进行加工、整理、统计与分析,进一步的利用人工智能算法定量刻画二氧化碳指标与PM2.5数据的关系,实现模拟二氧化碳对PM2.5的影响这一目标。以下对技术路线中的核心技术与方法(模型算法、特征构建)做出简要介绍,并对模型结果进行说明。
算法简介
项目中针对预测目标的模型包括随机森林、XGBOOST以及卷积神经网络(CNN)。其中随机森林与XGBOOST属于集成学习,集成学习的思想是组合多个弱监督模型以得到一个更好更全面的强监督模型,相较于单一模型,集成学习往往有更好的效果。CNN属于深度学习算法,常用于图像识别问题,本项目中每个环境监测站点与周围网格点组成的特征集合可以看作一幅图像,CNN算法符合本项目的业务实际。
针对仿真目标的模型主要采用非负Lasso回归(Non-negative Lasso Regression)方法。非负Lasso回归具有良好的解释性,满足仿真的需求。
此外,针对数据量不足的情况,项目主要采用空间插值中常用的克里金插值算法扩充数据。以下分别简要介绍上述五种算法。
1) 随机森林
随机森林顾名思义,是用随机的方式建立一个森林,森林由很多决策树组成,每次决策由所有决策树共同决定。
2) XGBOOST
XGBOOST也是集成方法的一种,与采用Bagging策略的随机森林不同,XGBOOST使用的是Boosting策略。Bagging策略中每个弱监督模型相互独立,最终决策由多个弱监督模型投票做出;Boosting策略中,弱监督模型之间存在序列上的关系,每个弱监督模型都是通过优化上一个模型的损失得到。
3) CNN
CNN是深度学习的一种,常用与图像识别。该算法通过卷积与池化提取图像的主要特征,再对设定的损失函数利用反向传播算法就可以求解得到模型参数。
4) 非负Lasso回归
非负Lasso回归是指在线性回归的基础上添加L1正则项(Lasso),并且限制回归系数不为负。其优点在于:1)线性回归保证模型具有良好的解释性;2)Lasso部分可以压缩不重要的变量,去除指标共线性,防止过拟合,提升模型泛化能力;3)非负部分确保了模型系数与实际业务一致(二氧化碳的提升会导致PM2.5的上升)。
非负Lasso回归的目标函数如下:
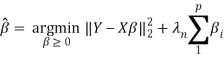
其中,![]() 表示模型系数,
表示模型系数,![]() 为平方误差,
为平方误差,![]() 表示正则项,
表示正则项,![]() 为正则项的权重系数。
为正则项的权重系数。
5) 克里金插值
克里金插值是空间插值的主要方法之一,包括普通克里金、简单克里金等,这里主要介绍项目中使用的普通克里金。普通克里金插值假设,空间中某点的估计值为周围n个点的加权平均:![]() =
= ![]() ,其中
,其中![]() = 1,在此约束条件下,求目标函数的极值:
= 1,在此约束条件下,求目标函数的极值:
![]()
进一步可以求解。
特征构建
每个监测站点作为一条数据样本,因变量为站点的PM2.5数据,自变量为站点向外拓展n圈的网格点的所有二氧化碳指标。如下图所示(n=3),红色点表示站点,每个方框表示网格。
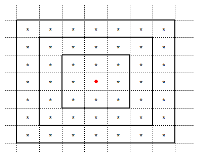
图2 模型样本空间示意图
项目中采取三种方式处理数量庞大的自变量,不同处理方式对应不同算法。
1) 平铺。对于每个站点,将站点对应的所有网格的二氧化碳指标平铺展开成一行。具体而言,第一个网格的13个二氧化碳指标作为站点对应的1-13个指标,第二个网格的13个二氧化碳指标作为对应的14-26个指标,以此类推。这种方式适合随机森林与XGBOOST模型。
2) 卷积。将网格对应的13个指标看作13个通道,每个通道上包含![]() 网格点,进一步的通过卷积与池化提取出局部地区的主要特征。这种处理方式适用于CNN。
网格点,进一步的通过卷积与池化提取出局部地区的主要特征。这种处理方式适用于CNN。
3) 平均。对每圈中所有的网格的指标求平均值作为新的指标,平均之后每圈都只包含13个指标。这种处理方式假设位于同一圈中的不同网格二氧化碳对于监测站点PM2.5的影响是相同的。这种方式的优点是能够显著的减少指标数量,向外拓展n圈时的指标数量为(n+1)*13,指标数量相对较小,适合非负Lasso回归模型。
模型训练
预测模型追求精度高、误差小。模型训练时,针对不同数据处理方式(向外拓展圈数、克里插值数据量)、不同模型(随机森林、XGBOOST、CNN)尽可能多的组合不同条件分别训练模型,选取误差最小的模型。
仿真模型注重解释性,项目中使用非负Lasso回归模型进行训练。在模拟时,为保证监测站点周围的每个网格点的每个指标对监测站点的PM2.5数据都有一定的影响(业务实际),模型训练时分为两阶段:
1) 第一阶段只使用二氧化碳总排放指标建立非负Lasso回归模型,拟合PM2.5数据。
2) 第二阶段中,计算第一阶段拟合的残差作为因变量,使用剩余的二氧化碳指标作为自变量,再次建立非负Lasso回归模型。
这样,当改变某个二氧化碳指标模拟PM2.5变化时,该变量一定会通过改变二氧化碳总指标对PM2.5产生一定的影响。
模型效果
模型效果使用MAPE(Mean Absolute Percentage Error)进行评价,MAPE表示平均百分比的绝对误差,其计算方式如下:
![]()
其中,n表示样本数量,![]() 表示真实值,
表示真实值,![]() 表示预测值。
表示预测值。
评价时采用交叉验证的方式。具体而言,每次训练时将待训练数据按照7:3划分为训练集与测试集,训练集用于训练模型;对于训练好的模型,在测试集上计算其对应的MAPE值。用交叉验证来评价模型可以保证模型评价是稳健的、可信的。
预测模型中的最好效果对应随机森林模型向外拓展5圈且不使用克里金插值,其测试集MAPE为13.75%。对测试集中每个样本计算误差值,得到如下误差分布图。(图形表示在测试集444个样本中,220个样本的误差在0-5之间)
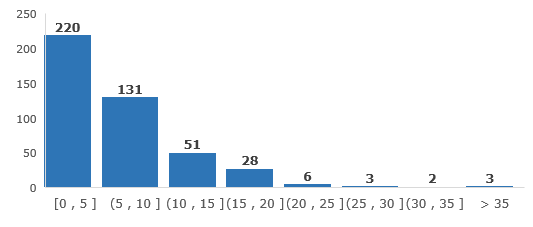
图 3 随机森林预测误差分布图
仿真模型最好的效果对应非负Lasso回归向外拓展3圈,其对应的MAPE为26.39%。对测试集中每个样本计算误差值,得到如下误差分布图。
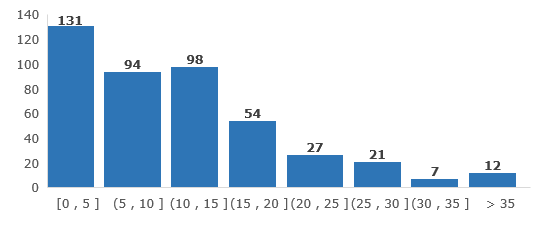
图 4 非负Lasso预测误差分布图
在平台系统开发中,与模型相关的业务场景是:某个网格中的二氧化碳指标变化,对周围监测站点PM2.5浓度的增量有何种影响。仿真模型更加符合这一场景,因此平台中使用上述仿真模型(非负Lasso模型)。
(三)基础数据
二氧化碳排放网格数据来自:中国高空间分辨率网格数据(China High Resolution Emission Gridded Database,CHRED)。
CHRED参考国际主流自下而上的空间化方法,结合中国的实际情况和数据特点,建立基于点排放源自下而上的空间化方法,结合点排放源(工业企业、污水处理厂、垃圾填埋场、畜禽养殖场/小区、煤矿开采、水运船舶等)和其他线源(交通源)、面源(农业、生活源等)数据,实现1 km CO2排放网格数据,及数据的空间精度和不确定性分析方法。CHRED数据突出排放的空间化和空间分布格局,强调排放数据的空间精度,当前已更新至3.0版本(2018年)。CHRED 3.0二氧化碳排放网格数据包括:工业、工业过程、农业、服务业、城镇生活、农村生活、交通(包括道路、铁路、水运和航空)排放。
中国空气质量数据来自中国环境监测总站发布的实时数据。本平台仅考虑PM2.5。